ctFS目标是利用Byte-addressable PM来降低文件访问开销。通过将文件表示为虚拟内存空间中连续的区域来利用内存管理与硬件。将offset转换为文件地址可以使用简单的数学运算,之后使用MMU将虚拟内存地址转换为物理地址。
Intel Optane DC的性能与内存是同一个数量级。Linux DAX消除了page cache并且直接访问PM。其他的设计绕过了切换到内存的开销。
PM减少了内存和可持久存储之间的性能差距,瓶颈从IO转移到了文件索引。在ext4-DAX中文件追加操作的过程中,索引的开销占了45%
使用连续文件分配可以代替索引结构,但是
- 固定分区中的内部碎片
- 可变分区中的外部碎片
- 文件大小改变
ctFS使用了连续文件分配,并且利用了硬件实现地址翻译。ctFS包括以下设计元素:
- 每个文件分配在64bit虚拟内存空间中。因此可以利用现有的MMU硬件,即使文件的物理内存地址并不连续。64bit空间对于任何文件系统来说都足够大。此外,虚拟内存空间使用层次管理,类似于伙伴系统。每个分区可以被分成8个子分区,这样的设计加速了分配,避免了外部碎片,最小化内部碎片。
- 一个文件的虚拟到物理映射由persistent page tables(PPT)管理。PPT类似于普通的page tables,但是PPT持久的保存在PM中。当ctFS区域出现了page fault时,操作系统在PPT中查找并在页表中创建映射。
- 最初,一个文件分配在正好能够放下文件大小的分区中。当文件大小增长超过了分区,他将会移动到更大的分区中,同时因为虚拟地址的转换,不需要拷贝实际的数据。ctFS使用原子交换
pswap(),原子的交换虚拟地址到物理地址的映射。
在ctFS中,从文件偏移量到物理地址的翻译需要经过虚拟地址物理地址映射,这并不比传统的文件到block索引简单。关键的区别在于页表翻译可以使用现有的硬件加速。翻译被TLB缓存,并且对于软件透明且只需在一个周期内完成。作为对比,文件系统的文件到blcok翻译只能被软件缓存。另外,ctFS可以利用多种内存映射的优化,例如Huge Pages。
ctFS的一个限制是我们在用户空间中实现了library,用安全交换了性能。虽然最大化的性能绕过了内核,但是这样牺牲了安全性。
Analysis of File Indexing Overhead
我们分析了ext4-DAX与SplitFS中block翻译的性能开销,使用了六种基准测试。实验在一个配有256G Intel Optane DC可持久化内存Linux服务器中进行。
![[Pasted image 20220316145549.png]]
在ext4-DAX中,我们观察到索引开销在Append与SWE中较为明显,,占了45%的总体运行时间。在这两种实验中,索引时间包括了构建索引的时间。对于随机速写,RR与RW中,索引时间占比18%与15%。
与ext4-DAX相比,SplitFS在索引中花费了更高的时间,Append(63%)、SWE(45%)、RW(38%),即使总的运行时间更短。这是因为SplitFS转移了瓶颈加剧了索引开销。SplitFS将文件逻辑分为用户空间U-Split与内核空间K-Split,K-Split复用了ext4-DAX。文件被U-Split划分为多个2MB的区域,每个区域映射到了ext4-DAX文件。U-Split与K-Split都参与了索引,U-Split将对应的逻辑索引映射到对应的ext4-DAX文件,同时K-Split检索索引来获取真正的物理地址。
SplitFS索引时间主要来自于在处理page fault时的kernel索引,SplitFS将所有的读写转换为内存映射IO,因此每个操作都会触发page fault,由此来触发kernel索引。
作为对比,ctFS成功的消除了大部分索引时间,在6个测试中,大部分的运行时间花费在了IO上而不是索引。ctFS相比ext4-DAX实现了7.7x的提升,相比SplitFS实现了3.1x的提升。
SplitFS与ctFS有两种模式,Sync与Strict。Figure 1来自于Sync模式,因为这与ext4-DAX提供了相同的崩溃一致性。Strict模式提供了更强的崩溃一致性,与NOVA和pmfs类似。
Overview of ctFS
ctFS是一个高性能PM文件系统,在用户空间中访问与管理文件数据与元数据。每一个文件在虚拟内存中连续存放,ctFS将传统文件系统的offset-to-block翻译offload给了内存管理子系统。除此之外,ctFS提供了一个高效的原语pswap在避免double write的同时确保了数据一致性。ctFS的写操是一致的,写操作在完成前会持久在PM上。所有的写入直接写入到PM中而不需要DRAM缓存。
![Pasted image 20220316160153.png]
ctFS的结构,包括了两个部分
- 用户空间的系统库,ctU,提供了文件系统抽象
- 内核子系统,ctK,管理虚拟内存抽象
ctU实现了文件系统结构并且映射到虚拟内存空间,ctK使用储存在PM中的PPT将虚拟内存映射到了物理内存。ctU中的page fault由ctK来处理。如果PPT中不包含对应地址的映射,ctK会分配一个PM Page,建立映射,将PPT拷贝到DRAM页表中,之后的翻译就由MMU执行。当PPT中的映射过期后,ctK将会从页表中移除相应的映射,并且在TLB中去除。
File System Structure(ctU)
ctU将虚拟内存空间组织为分层的结构以利用连续分配。相同层的分区大小相同,上一层的分区大小是下一层的8倍。

最低的一层L0为4KB大小。
一个文件或者目录只会放在一个能够容纳文件大小的最小分区中。
上一层是下一层的8倍大小可以对齐Linux页表。可以优化pswap
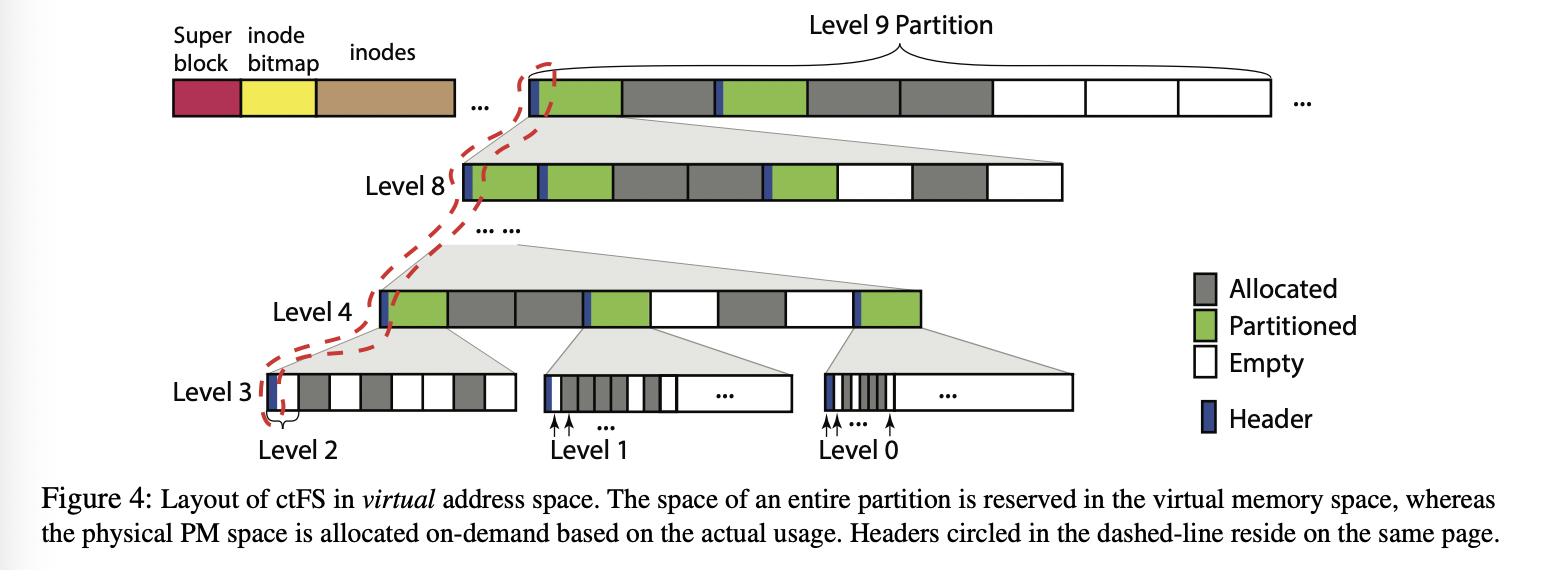
虚拟内存划分为两个L9分区,第一个L9分区用来存储元数据:一个superblock,inode的bitmap,与inode本身。inode保存文件元数据(owner、group、protection、size等)与一个标识包含文件数据的起始虚拟内存地址。inode bitmap用来标识inode是否被分配。第二个L9分区用来数据。注意这里的L9只是虚拟内存地址,真正的物理内存按需分配。
每一个分区可以是以下三种状态之一:A(llocated)、P(artitioned)、E(mpty)。A状态的分区被分配给了一个文件,P状态的分区分成了8个下一级的分区。高一级的分区为低一级分区的父分区。父分区包括了八个子分区。因此分区是分层组织的。
分层的结构有三个特性:
- 对于任何一个分区,所有祖先都是P状态。对于A与E的分区没有儿子
- 任何分区的地址都在其祖先分区内
- 无论哪一层的分区的起始地址都是与分区大小对其的
ctU需要维护每一个分区的分配情况以及状态,所以在每个P状态的分区的头包含了每个子分区的状态。ctU将header保存在分区的第一个页中。
为了加速分配,header包括available-level字段标识了子分区中最高可用分区的等级。Fugure4中的L9分区的available-level就是8:因为有一个L8子分区处于E状态。有了这个状态当需要分配N等级的分区时,如果一个P分区的available-level小于N,ctU就不需要往下查找了。这样我们有了固定的最坏时间复杂度。
header放在了每个P分区的第一个页中,所以第一个子分区有着相同的header,第一个子分区也必须是P状态,但是这样第一个分区就不能保存数据了(A状态)。因此一个header可以包含层次结构中多个分区的header。在Figure4中的分区的header保存在相同的page中,通过讲header的空间划分成L4-L9来实现。
ctU不允许L0-L3的分区分割因为4KB的header对于小的分区来说太浪费了。所以每个L3分区只能分割为512个L0、64个L1或者8个L2分区。因此L3分区只有一个header标志是否为P。子分区的状态只能为A或E。
Kernel Subsystem Structure(ctK)
ctK管理PPT并且实现了pswap。PPT的结构与Linux的4级页表相同,有两个不同:(1)PPT存在PM中因此是可持久化的(2)对于虚拟地址与物理地址都是用了相对地址,因为地址随机化,ctFS的区域在不同的进程中可能被映射到不同的内存区域。同时硬件的重新配置会改变物理地址的起始。每一个进程有页表,ctK只有一个PPT包含了ctU中所有虚拟地址的映射。PPT不能被MMU访问,所以PPT中的映射需要在page fault的时候按需移动到页表中。
pswap原子的移动PPT中两个相同大小的连续区域。
1 | int pswap(void* A, void* B, unsigned int N, int* flag); |
A与B是每一个page的起始地址,N是page的数量,flag是输出参数。pswap移动成功后会将flag设置为1。ctU将flag设置为指向redo log中的变量来决定在crash后是否需要redo。同时pswap会将所有的内存页表中的映射置为无效。
pswap保证了一致性,并且所有的操作都是持久化的。同时pswap保证了他们是可串行化的,保证了不同进程之间的隔离。
pswap只交换对应页表的内容。
为什么有下降:超过256个PTE后,可以直接移动PMD,然后把512减去PTE的数量移动回来,所以下降。
pswap两种应用场景,一是追加写入触发了升级到更大的分区或者trunc到了更小的分区,ctU使用pswap来原子改变映射。二是pswap可以在任意数据上支持原子写入,ctU先将数据写入到暂存区,当写入完成后,将暂存区与目的交换。
Performance
使用YCSB在ctFS上测试了LevelDB。YDSB包括了6种场景,A update heavy B read mostly C read only D read records that were recently inserted E range query F read-modify-write
ctFS在write-heavy的场景提升最大,相比SplitFS提升1.82x,相比DAX平均提升2.88x。
在strict mode中,ctFS超过SplitFS 1.3x。在read-heavy读workload的提升小一些,平均1.25x
感悟
- 利用了现有的硬件加速了原来软件实现的翻译过程