Raft 6.824的Lab2是要实现一个Raft共识算法 ,Raft主要包括leader选举、日志复制、安全性保证三部分,在Lab2的A和B中实现,在C中实现快照功能。
对Go语言不熟悉确实是一个难点…
实验目标
实现Leader选举:在长时间没有收到心跳包后成为Candidate发送投票请求,成为Leader
心跳包:实现Leader与Folllower之间的心跳包
需要注意的
Lab的提示中建议使用time.Sleep来做一些周期性的事件,但是我发现time.Timer有时候更好用(因为不需要手动管理锁)
test限制了每秒不超过十次的心跳包,这里我选择了150ms,选举超时时间为400-800ms
记得要重置选举计时器
关键代码 Raft结构体 首先是在Raft结构体中添加一些需要的字段,注意在Lab2A中不是所有的figure2A中提到的字段都需要用到,目前只需要添加需要用到的即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 type Raft struct { mu sync.Mutex peers []*labrpc.ClientEnd persister *Persister me int dead int32 electionTimer *time.Timer stopCh chan bool role role currentTerm int votedFor int log []LogEntry }
这里设置了electionTimer用来做选举超时的计时器,如果electionTimer超时则进入选举过程
选举 一个节点在超时后进入Candidate后需要将当前的term+1,并且向所有的节点发起RequestVote RPC。
其中有几点需要注意:
如果RequestVote的返回Term大于当前Candidate的Term,则需要回到Follower角色
要注意election超时的情况,这里我复用了electionTimer,既作为Follower的超时开始选举,也用作election超时
发送RequestVote时的Term与统计完票数后的Term可能不同,这一点在提示 的Rule5中提到了
记得释放锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 func (rf *Raft) rf.mu.Lock() if rf.role == Leader { rf.mu.Unlock() return } rf.role = Candidate rf.currentTerm++ rf.votedFor = rf.me lastLogTerm, lastLogIndex := rf.lastLogTermIndex() DPrintf("%v at %v start election\n" , rf.me, rf.currentTerm) args := RequestVoteArgs{ Term: rf.currentTerm, CandidateId: rf.me, LastLogTerm: lastLogTerm, LastLogIndex: lastLogIndex, } rf.mu.Unlock() grantedCount := 1 voteCount := 1 votesCh := make (chan bool , len (rf.peers)) for idx := range rf.peers { if idx == rf.me { rf.resetElectionTimer() continue } go func (ch chan bool , idx int ) reply := RequestVoteReply{} rf.sendRequestVote(idx, &args, &reply) ch <- reply.VoteGranted if reply.Term > args.Term { rf.mu.Lock() if reply.Term > rf.currentTerm { rf.stepDown(reply.Term) rf.mu.Unlock() return } rf.mu.Unlock() } }(votesCh, idx) } for { r := <-votesCh voteCount++ if r == true { grantedCount++ } if voteCount == len (rf.peers) || grantedCount > len (rf.peers)/2 || voteCount-grantedCount > len (rf.peers)/2 { break } } if grantedCount <= len (rf.peers)/2 { DPrintf("%v failed become leader\n" , rf.me) rf.mu.Lock() rf.role = Folllower rf.mu.Unlock() return } rf.mu.Lock() if args.Term == rf.currentTerm && rf.role == Candidate { DPrintf("%v become leader\n" , rf.me) rf.role = Leader go rf.tick() } rf.mu.Unlock() }
发送RequestVote RPC 这一段代码比较简单,使用了Sleep来等待
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func (rf *Raft) int , args *RequestVoteArgs, reply *RequestVoteReply) bool { ch := make (chan bool , 1 ) r := RequestVoteReply{} go func () ok := rf.peers[server].Call("Raft.RequestVote" , args, reply) ch <- ok }() time.Sleep(RPCTimeout) if <-ch { return true } return false }
RequestVote 收到投票请求后,需要判断下请求投票的节点的Term与当前节点的Term,收到RPC后节点回到Follower角色
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func (rf *Raft) rf.mu.Lock() defer rf.mu.Unlock() DPrintf("%v is requested to vote %v at term %v\n" , rf.me, args.CandidateId, rf.currentTerm) reply.Term = rf.currentTerm reply.VoteGranted = false if args.Term < rf.currentTerm { return } else if args.Term == rf.currentTerm { if rf.role == Leader { return } if rf.votedFor == args.CandidateId { reply.VoteGranted = true return } if rf.votedFor != -1 && rf.votedFor != args.CandidateId { return } } if args.Term > rf.currentTerm { rf.stepDown(args.Term) } rf.currentTerm = args.Term rf.role = Folllower rf.votedFor = args.CandidateId reply.VoteGranted = true DPrintf("%v vote to %v\n" , rf.me, args.CandidateId) rf.resetElectionTimer() return }
心跳包 在Lab2A中,AppendEntries RPC只用来作为心跳包。实现了tick函数,在节点成为leader后调用,定时的向其他节点发送心跳包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func (rf *Raft) for idx := range rf.peers { if idx == rf.me { rf.resetElectionTimer() continue } go rf.sendAppendEntries(idx) } } func (rf *Raft) timer := time.NewTimer(HeartbeatTimeout) for { select { case <-timer.C: if _, isLeader := rf.GetState(); !isLeader { DPrintf("%v stop tick\n" , rf.me) return } DPrintf("Leader %v tick\n" , rf.me) go rf.sendHeartbeat() timer.Reset(HeartbeatTimeout) case <-rf.stopCh: return } } }
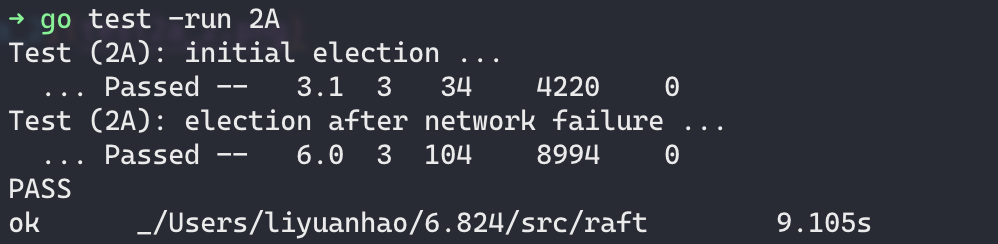
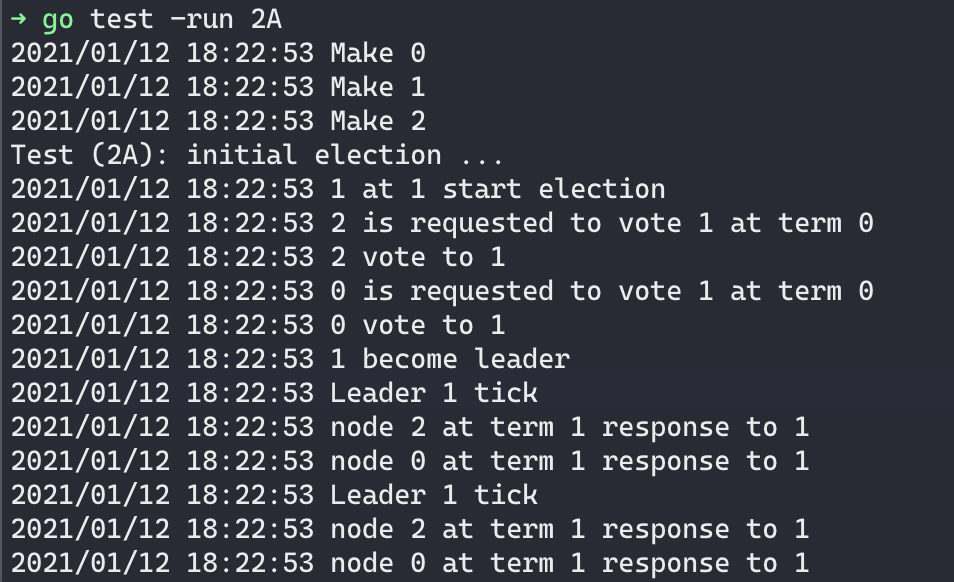
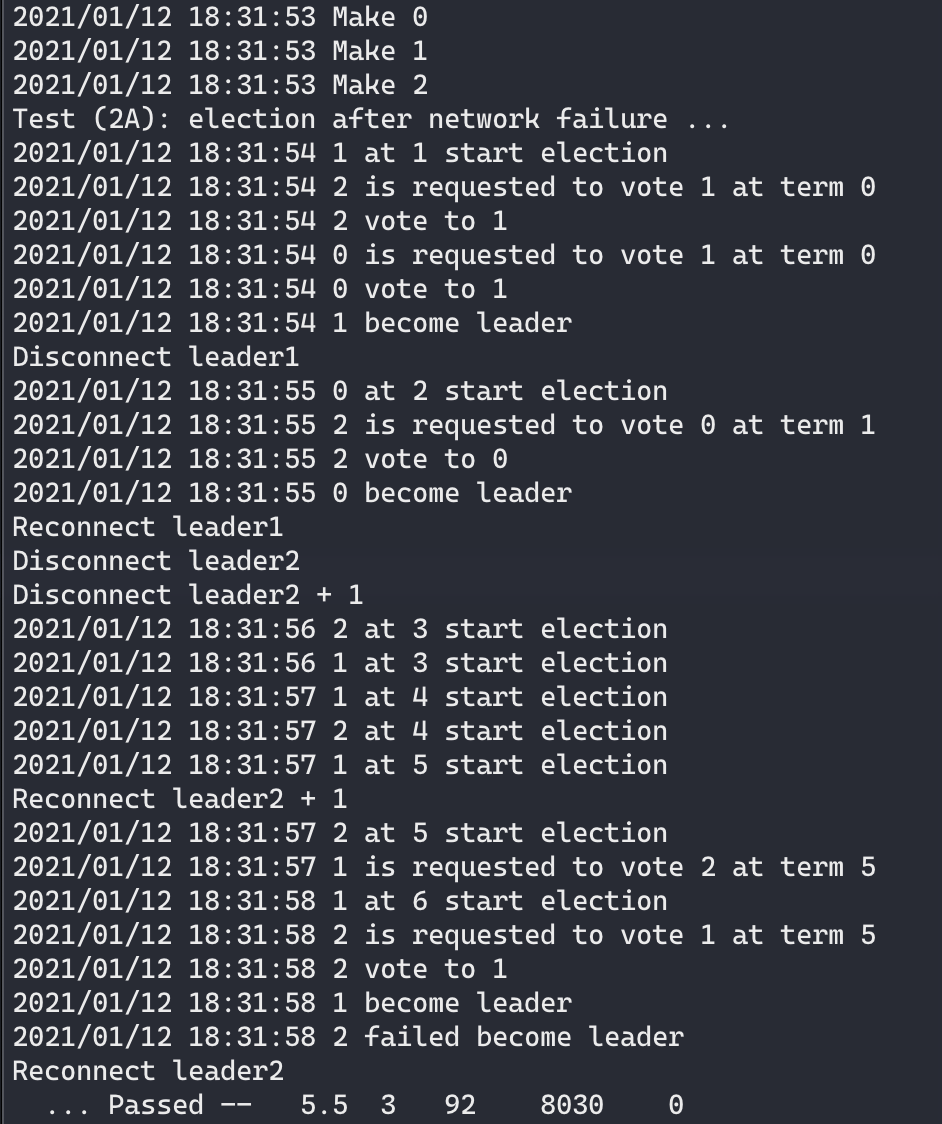
运行结果
Test (2A): initial election … 这一阶段就是在一切正常的情况下能够选出来leader就可以了
Test (2A): election after network failure … 在第二个test中,需要解决网络断开的问题:
在leader1断开后,剩余的两个节点能够选取出leader2
在leader1重新加入网络后,因为leader1的term已经落后,所以回到Follower
断开两个节点后没有任何一个节点能够获得多数票
接入一个节点后,重新选举出leader