测试
- TestPersist12C:测试持久化
- TestPersist22C:更多的持久化
- TestPersist32C:处理Leader分区及Follower重启
- TestFigure82C:处理论文中Figure8的场景,(只能commit当前term的log)
- TestUnreliableAgree2C:在不可靠网络环境下的共识
- TestFigure8Unreliable2C:在不可靠环境下的Figure8情况
- TestReliableChurn2C:这个应该是…乱搅?
- TestUnreliableChurn2C
测试脚本
因为很多问题只有在多次的运行中才会出现,所以这里有一个测试脚本可以快速的进行数次测试
1 |
|
持久化
持久化主要是persist与readPresist两个函数,按照示例来实现就可以了
1 | func (rf *Raft) persist() { |
1 | func (rf *Raft) readPersist(data []byte) { |
然后记得要在修改了non-volatile状态后调用函数进行持久化
Unreliable
首先增加persist相关的代码,通过了前边几个测试
然后挂在了TestUnreliableAgree2C,再去仔细阅读下Student’s guide
Follow Figure 2’s directions as to when you should start an election. In particular, note that if you are a candidate (i.e., you are currently running an election), but the election timer fires, you should start another election. This is important to avoid the system stalling due to delayed or dropped RPCs.
当electionTimer触发时,应该创建一个goroutine来运行election函数,然后还是不行。。。。
经过检查log,发现在follower上出现了
[{1 3} {1 301} {1 300} {1 302} {1 303} {1 303} {1 4} {1 401} {1 400} {1 402}]
中间303的log重复了
经过debug发现是这里有问题
1 | i := 0 |
这是找到第一个冲突log的部分,原来的代码是如果cur=lastLogIndex跳出循环,但是这样是不对的,在下一个循环中会造成最后一项重复
然后在TestFigure8Unreliable2C又挂了
config.go:481: one(1962) failed to reach agreement
经过查看log发现是因为达成一致性超时了
1 | for i, e := range rf.log { |
这里的conflictindex应该是冲突的term第一个log,但是我一开始忘记了break。。。
然后再仔细读了下,有三种重置electionTimer的情况
a) you get an AppendEntries RPC from the current leader (i.e., if the term in the AppendEntries arguments is outdated, you should not reset your timer);
b) you are starting an election; or
c) you grant a vote to another peer.
其中第三条是投票给其他人时应该重置计时器
还有一点是
Ensure that you follow the second rule in “Rules for Servers” before handling an incoming RPC. The second rule states:
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
我在Append Entries忘记了stepDown的过程
然后查看log,发现因为unreliable RPC导致了投票需要很久才能选举出Leader(因为Request Vote的返回丢失,虽然Follower同意投票但是Candidate没有接收到投票导致失败),所以我增加了重复发送RPC的机制。
将Request Vote和Append Entries都增加了重复发送机制后(同时要增加处理重复过时RPC的机制),总算是通过了这个test(1200次零错误)。
结果
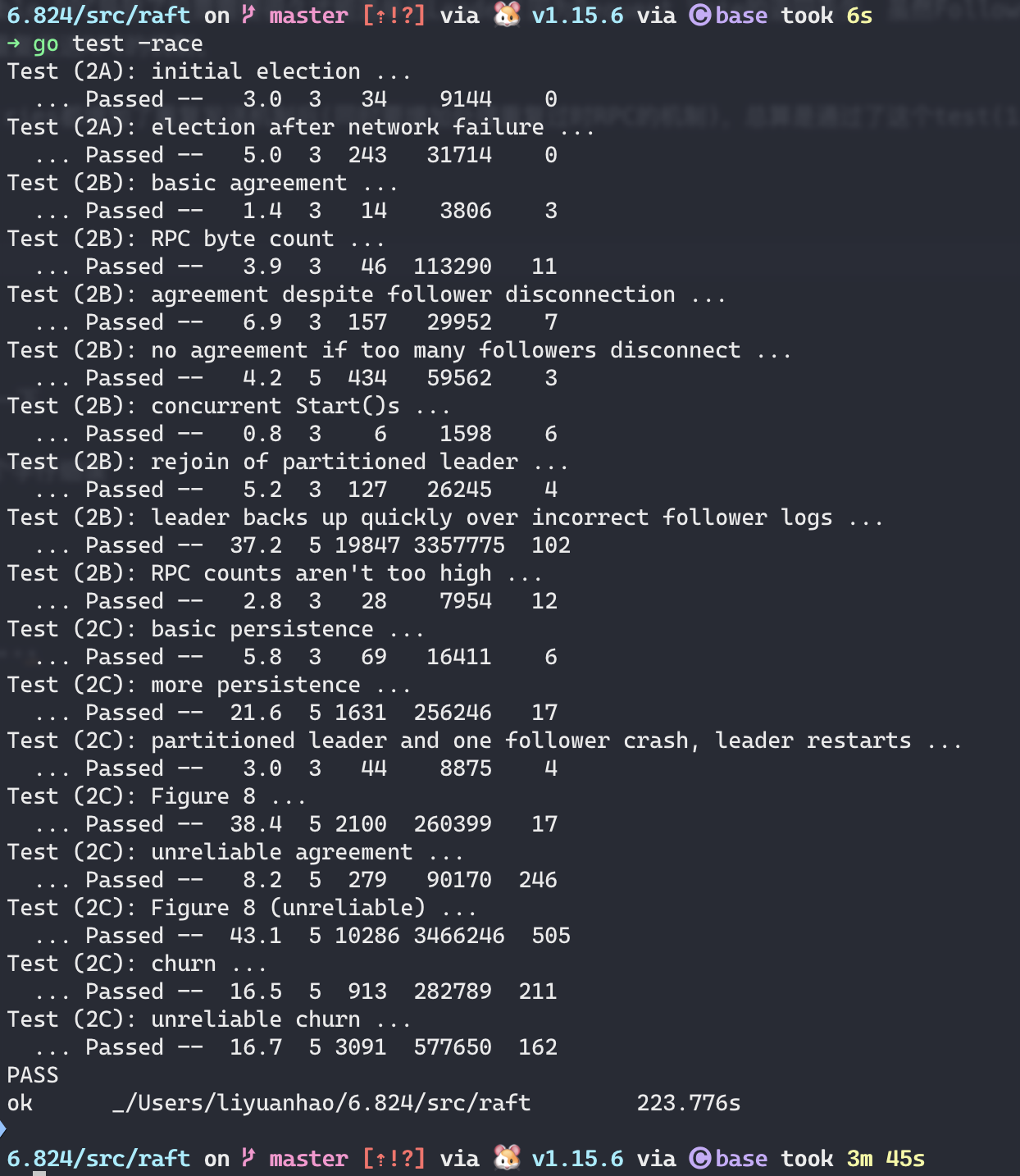
后记
这次Lab也算是踩了不少坑,总结一下
- 一定一定要把Figure2A每一个字仔细读
- 记得要看Student’s guide
- 出现问题打log一个个分析
- 使用小黄鸭调试法
等到以后再来重构下这次的代码吧…